fail#1 archviz
archviz-fail
This is a post to document my attempt at disrupting vray/enscape using AI. It failed, but the history is valuable (to me, at least).
Goal + Motivation
The goal of this project was to create a one-button-magic UX to substitute VRAY for interior design renders. I was motivated by advances in AI image models, specially after OpenAI released what was to become the gpt-image-1 model.
Architects and interior designers spend a significant amount of time generating photoreal images using VRAY/Enscape, which require (i) a robust computer (costly), (ii) specific knowledge on the use of these tools (scarce resource) and (iii) significant productive downtime (productivity sink). Thus, leveraging AI that could get ~95% of the work right and done in seconds instead of hours, without costly equipment or specialized knowledge was a sure-fire way to generate value.
Attempts
1. ComfyUI
My first attemp was using ComfyUI to create specific flows in order to achieve both photorealism, but also to understand style in an automatized way.
For this, I relied mainly on opensource models, be them the base models or optimized by other people, along with canny and depth models to ensure fidelity.
Difficulties
Diffuser models are default creative, and to enable them to edit a scene you need to allow them to be creative. This is solvable through iteration on parameters, but created shake ground between scenes. A set of params for a given scene might not work for another one.
These models always need a style guidance, as they're bad at understanding subtle context from an image. This is solvable by using an LLM to describe your image, or it's style, to the model, or to allow the user to select the style. The first solution might hallucinate, the second disrutps the "one-button-magic" flow, but both are minor issues.
Running these models locally is a tough job. When I tried using a refiner model along the base model, my setup failed me. I'm on MBP Pro w/ M4Pro chip and 24GB RAM. This is solvable by either local optimization of the models (which my skills weren't sufficient to solve) or going to a cloud environment such as FAL or Replicate's services.
Killer difficulty: diffuser models are default glossy in visual, and usually tend to render poshy scenes, even when given minimalist/modern inputs for style. This is hard to bypass w/o fine tuning your own model. Then again, you'd have to switch models per inferred or given style input, making the solution bulky.
I was making good progress with ComfyUI, but the hardship in testing locally faster and making the models obey styleguides made me think this wasn't the right path. It was not, however, and exhausted one.
 Input image
Input image

ComfyUI's best result
2. gpt-image-1
When OpenAI released gpt-image-1 within ChatGPT-4o, it seemed like the pivotal moment for me to launch the VRAY killer. Prompting it with "make this image photorealistic" delivered a very good result, even if not 95% correct vs what was expected from a VRAY render.
Input image

ChatGPT First Pass
I got to working on a proper frontend flow, and making sure the workflow was seamless. Didn't need a fancy solution or interface, but wanted to having something usable for dogfeeding purposes (my wife is an architect with a studio which employs people that do renderings with VRAY). I attached Google's gemini-flash-2.0-exp model to generate images just to see it working all the way, and it did. When OpenAI finally release gpt-image-1, I was thrilled: I had it done to be shipped in ~1 day - just needed to solve auth and db, iterate a bit on the prompt and I was done.
Except I wasn't - iterating on the prompt didn't quite solve it. The prompts.txt file show's the different versions I've used, and none delivered the quality I was expecting.
With the prompt iterations, I started iterating with OpenAI's o3, 04-mini and o4-mini-high to find alternatives to tame the model. They're excellent coworkers, albeit with an inferred idea on what is gpt-image-1 - they usually treated as a diffusion model, which I should be able to tweak prompt strenght, model creativity, use canny, depth, etc, along. I played with these ideas, to no avail. And I tried a lot of stuff. I learned a lot too (felzenswalb mapping is goat, and created by a brazilian, lfg!), which is the biggest win. I even think I understand a bit more on how gpt-image-1 works when editing images, which makes me aware of it's limitations, inspite of not having been able to get around them.
Difficulties
Auto-regressive image generating models are less documented and harder to manipulate then diffusion based models. They tend to be really precise against prompts and even images, but this makes manipulating them towards your goal, when super specific, harder.
gpt-image-1 is really too new (today is 2025-05-03, it was released as a standalone model less than 2 weeks ago), and needs improvement in a bunch of fronts (as acknowledge by OpenAI)
Killer Difficulty: in spite of all my efforts, hacking attempts, iterations, gpt-image-1 failed at specific points which were a no-go for me. It seems it uses internally a canny model and a color mapping of the image they mean edit, but they're soft enough to avoid creating artifacts (which is indeed the right choice for an all-purpose model, btw). And this made it impossible to manipulate elements to make them right.
And I tried! I paired gpt-image-1 with traditional canny, sobel, laplacian ones. Paired it with SLIC, Felzenswelb pixel mappings, with GMM, KMeans and Meanshift maps... to little to no avail.
I was iterating then with a different image, that seemed easier than my first one.
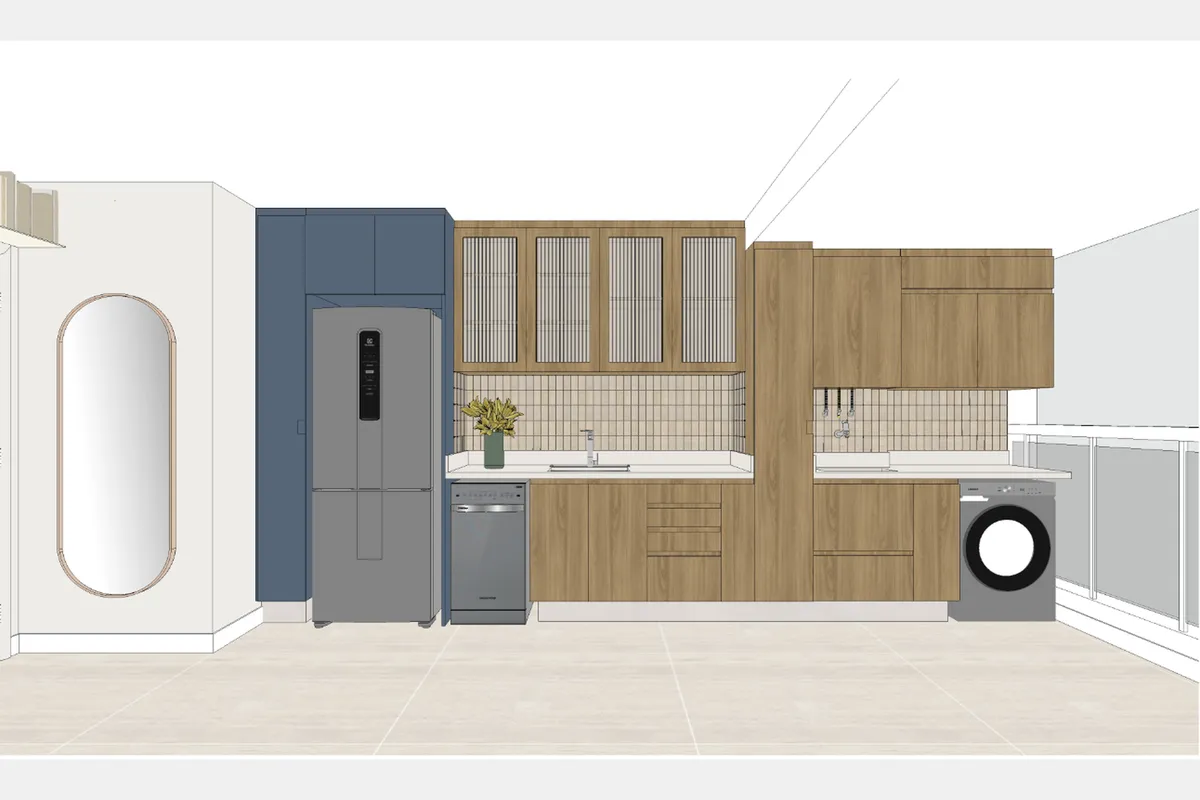 New input
New input
 A soft canny
A soft canny
 My SLIC input that gave me one good result, not reproducible
My SLIC input that gave me one good result, not reproducible
 My average/modal result
My average/modal result
 My best result, using canny, depth and SLIC boundaries
My best result, using canny, depth and SLIC boundaries
 The VRAY benchmark
The VRAY benchmark
Final thoughts
Working with cutting edge models is nice, but trying to make them work in precise ways, abstracting the actual interface they propose into buttons is still what I find to be the biggest challenge.
Most of the best AI-wrapper products (Lovable, Cursor) are still leaning on prompts, and leaving this mechanics exposed to the user. They're tooling the models quite a lot, and having them work with a bunch of extensions, but there's an interface of control given to users that make the outcome their co-responsiblity. Abstracting this and being totally responsible for an outcome is still a challenge to be won.
There are attempts I could make at this, using the "make AI-SaaS to make money" goal: fine-tune models per style or per studio, expose parameters, lower users' expectations as to what the end result should be. But as the main project and purpose of defeating VRAY, it's a fail.
It was a very cool one to work on, nonetheless.
Here you'll find the github repo with scripts I've used in this attempt, if you want to take a look. If you think you know how to solve this, let's chat! Let's have fun together.